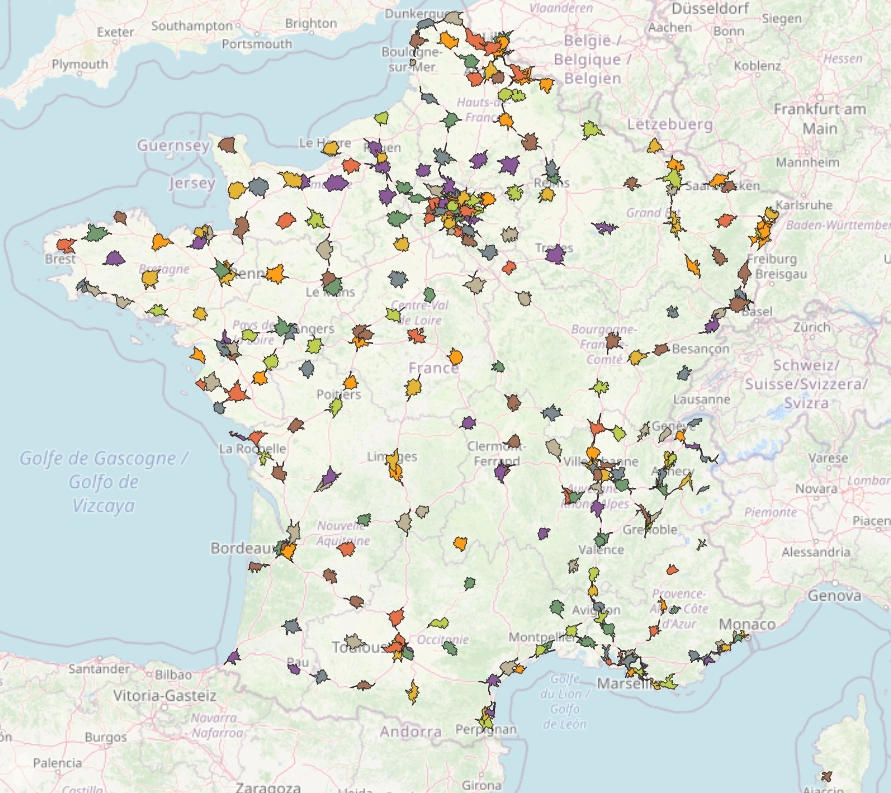
 Nous allons calculer les zones isochrones à 15 minutes des magasins Décathlon français, et les coupler avec les données géographiques de l'IGN croisées avec les données statistiques de l'INSEE.
Nous allons calculer les zones isochrones à 15 minutes des magasins Décathlon français, et les coupler avec les données géographiques de l'IGN croisées avec les données statistiques de l'INSEE.
L'ensemble formera de supposées zones de chalandise des magasins, particulièrement pertinentes car couplées avec de vraies zones isochrones. Nous calculerons aussi la cannibalisation des magasins, ainsi que leur proximité avec des équipements sportifs.
Pour ce faire nous n'utiliserons que des données en open-source, l'API d'openrouteservice, le logiciel libre QGIS et peut-être un peu de code Python.
Mots-clefs : géomarketing, IRIS, INSEE, IGN, OSM, SIG, BDD, traitement de données, SQL, zones de chalandise, indicateur, requête de regroupement, zones isochrones, Python
Enseignants responsables : Georges Hinot
Pré-requis : des notions sur QGIS ou autres SIG, des notions sur Excel ou autres tableurs.
Compétences visées : maîtrise théorique et technique des notions de base du géomarketing (zones isochrones, zones de chalandise, indicateurs, jointures et requêtes de regroupement).
Enjeux du cours : rendre autonome les étudiants sur la recherche et l’usage de données autour de problématiques géomarketing, faire « parler » la donnée, créer des indicateurs, veiller à la pertinence des données représentées.
Programme pédagogique : mise en situation autour d'une commande géomarketing impliquant la récupération, le traitement et la représentation de données. Selon l'avancée du cours, nous irons jusqu'à utiliser des fonctionnalités avancées de QGIS (SQL spatial) et Python (création de zones isochrones via une API et customisation du comportement de QGIS).
Le sommaire de droite et la navigation sous le texte vous permettent de vous déplacer dans ce tutoriel.
Récupération des magasins
QuickOSM et overpass
Commençons par récupérer tous les magasins de sport en France avec l'excellent plugin QuickOSM (key=shop ; value=sport ; in=France).
En réalité le plugin a quelques limitations, nous nous en servirons donc pour générer la requête, puis irons l'exécuter sur l'overpass-turbo (augmentez tout de même le timout). 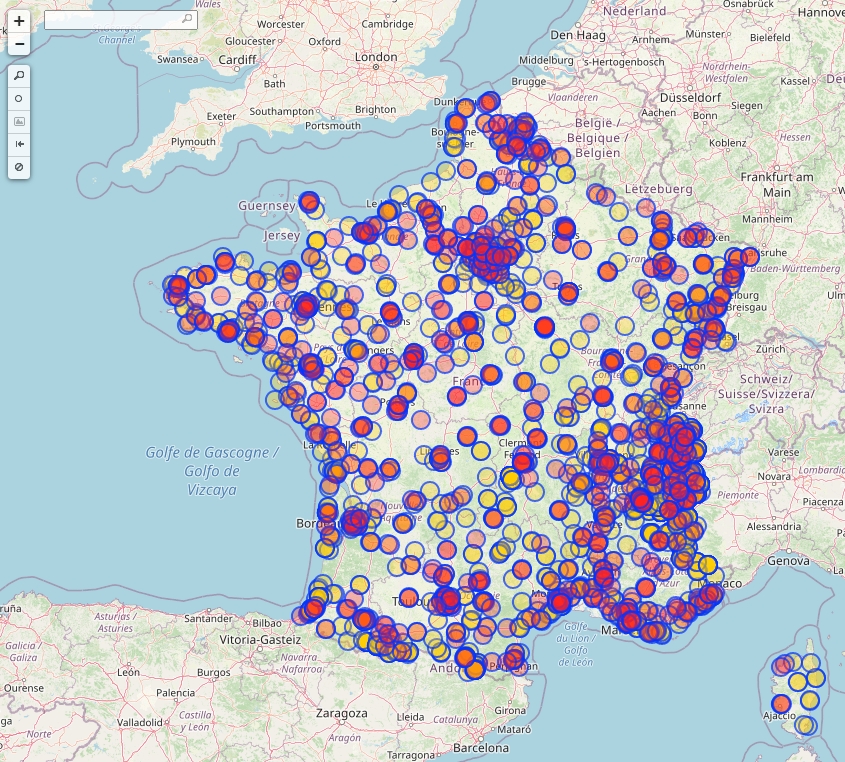
<osm-script output="xml" timeout="2500"> <id-query {{geocodeArea:France}} into="area_0"/> <union> <query type="node"> <has-kv k="shop" v="sports"/> <area-query from="area_0"/> </query> <query type="way"> <has-kv k="shop" v="sports"/> <area-query from="area_0"/> </query> <query type="relation"> <has-kv k="shop" v="sports"/> <area-query from="area_0"/> </query> </union> <union> <item/> <recurse type="down"/> </union> <print mode="body"/> </osm-script>
Importez le GEOSJON résultant dans QGIS. Nous nous retrouvons avec 706 polygones et 2378 points (27 décembre 2020). Si vous avez des difficultés d'export ou de connexion internet, le fichier GEOJSON exporté est un pièce jointe de cet article.
Explorez les données sous QGIS et son Field Calculator, le champ brand notamment.
Un shape propre
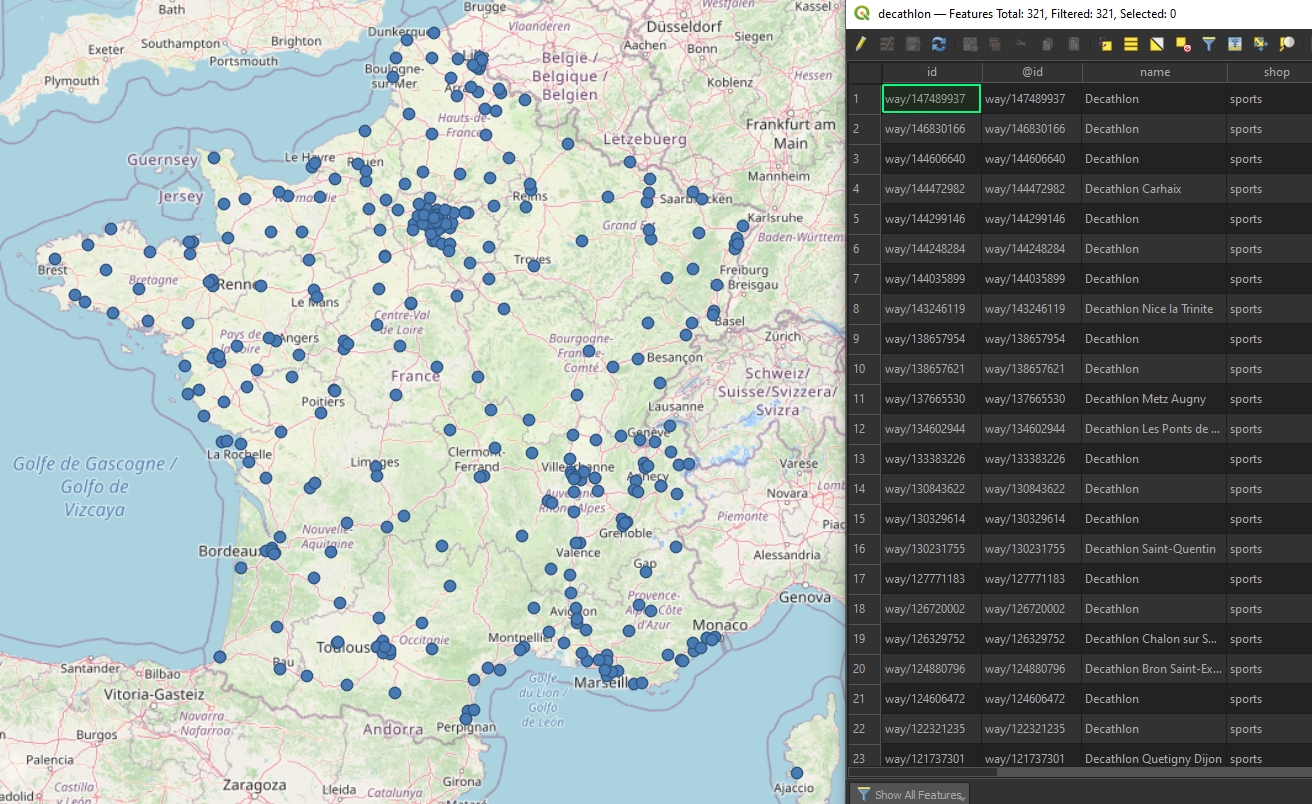 Pour plus de simplicité et d'efficacité dans les futurs traitements, exportez dans un seul shape les points et les centroïdes de polygones correspondants à brand=Decathlon en France Métropolitaine.
Pour plus de simplicité et d'efficacité dans les futurs traitements, exportez dans un seul shape les points et les centroïdes de polygones correspondants à brand=Decathlon en France Métropolitaine.
- Sur chaque couche, en mode édition, sélection manuelle de la France métropolitaine, inversion de la sélection, suppression de la sélection.
- Sur la couche polygonale, extraction des centroïdes (Vector/Geometry Tools/Centroids). Suppression de la couche polygonale.
- Sur chaque couche de points restantes, requêtes d'affichage (Properties/Source/Query Builder) des magasins Décathlon (attention aux valeurs distinctes) :
"brand" = 'Decathlon' OR "brand" = 'Decathlon Easy' OR "brand" = 'Décathlon' ...
- Fusion des 2 couches de points (Vector/Data Management Tools/Merge Vector Layers).
Un shape propre... en SQL spatial
Attention aux noms de couches s'il y a plusieurs types d'entités (points, polygones), car QGIS virtualisera des couches et les renommera.
SELECT REPLACE(REPLACE(REPLACE(id, 'node/', ''), 'way/', ''), 'relation/', '') AS id, type_origine, brand, ST_TRANSFORM(geometry, 2154) AS geometry FROM ( SELECT id, 'Point' AS type_origine, brand, geometry FROM export_60f6133c_444d_4dfa_830f_54bb60e39d70 UNION SELECT id, 'Polygone', brand, ST_CENTROID(geometry) FROM export ) WHERE (brand LIKE '%Decathlon%' OR brand LIKE '%Décathlon%') AND ST_WITHIN(ST_TRANSFORM(geometry, 2154), BUILDMBR(-272166, 6041954, 1668968, 7129915, 2154)) ; -- AND ST_WITHIN(geometry, ST_MAKEENVELOPE(xmin, ymin, xmax, ymax, SRID)) ;
Correction des erreurs OSM et des entités non-pertinentes
Logique de doublon
Cependant si vous explorez vos données, vous pouvez constatez de visibles erreurs, des magasins trop rapprochés pour être réellement distintcs, ce sont des doublons pour l'usage que l'on veut en faire (pas de vrais doublons en général, mais ils ne sont pas pertinents pour nos futures zones isochrones, qui se superposeraient inutilement). On peut parler d'une logique de doublon.
Issus sans doute d'erreurs de saisie, de déménagements récents, de représentation de hangars, zones de livraison ou magasins déportés, nous allons les identifier en fonction de leur distance à vol d'oiseau entre eux (outil Vector/Analysis Tools/Distance Matrix). Choisissez les champs id en input et output.
En classant votre couche de sortie des distances les plus courtes aux moins courtes, vous pourrez zoomer proprement sur les magasins trop proches et les examiner. Remarquez que la couche matricielle est constituée d'entités multi-parties (zommez sur l'une d'entre elles et/ou examinez votre table attributaire).
Remarquez également qu'au vu du fonctionnement de l'outil Distance Matrix (calcul de la distance de chaque entité par rapport à toutes les autres), vous avez des doublons géométriques naturels dans la couche de sortie (de vrais doublons cette fois). Naturels, car normaux, bel et bien voulus par l'outil Distance Matrix ; géométriques, car seules les géométries sont en doublons, les données attributaires sont bien différentes, hormis le calcul de distance bien sûr.
Analysez les résultats pour trouver la meilleure logique à suivre (quelques vérifications sur Google Map par exemple). Il semblerait qu'en dessous d'une distance de 1700 mètres entre les magasins il s'agisse d'erreurs. Au-delà de ces 1700 mètres, nous arrivons dans les grandes villes où la proximité de plusieurs magasins uniques est probable (Paris, Marseille...).
Au 27 décembre 2020, à partir des données OSM, nous identifions 26 magasins Décathlon dans une logique de doublon. Bien sûr nous pourrions les corriger manuellement (ou mieux : directement dans OSM), mais imaginez que vous ayez 100, 1000 ou même 10 000 points en doublons. Mieux vaut savoir les corriger à la chaîne sur votre SIG.
Correction
Nous allons ici récupérer des points entre les magasins à supprimer. Ensuite nous supprimerons ces magasins, et nous les remplacerons par nos nouveaux points.
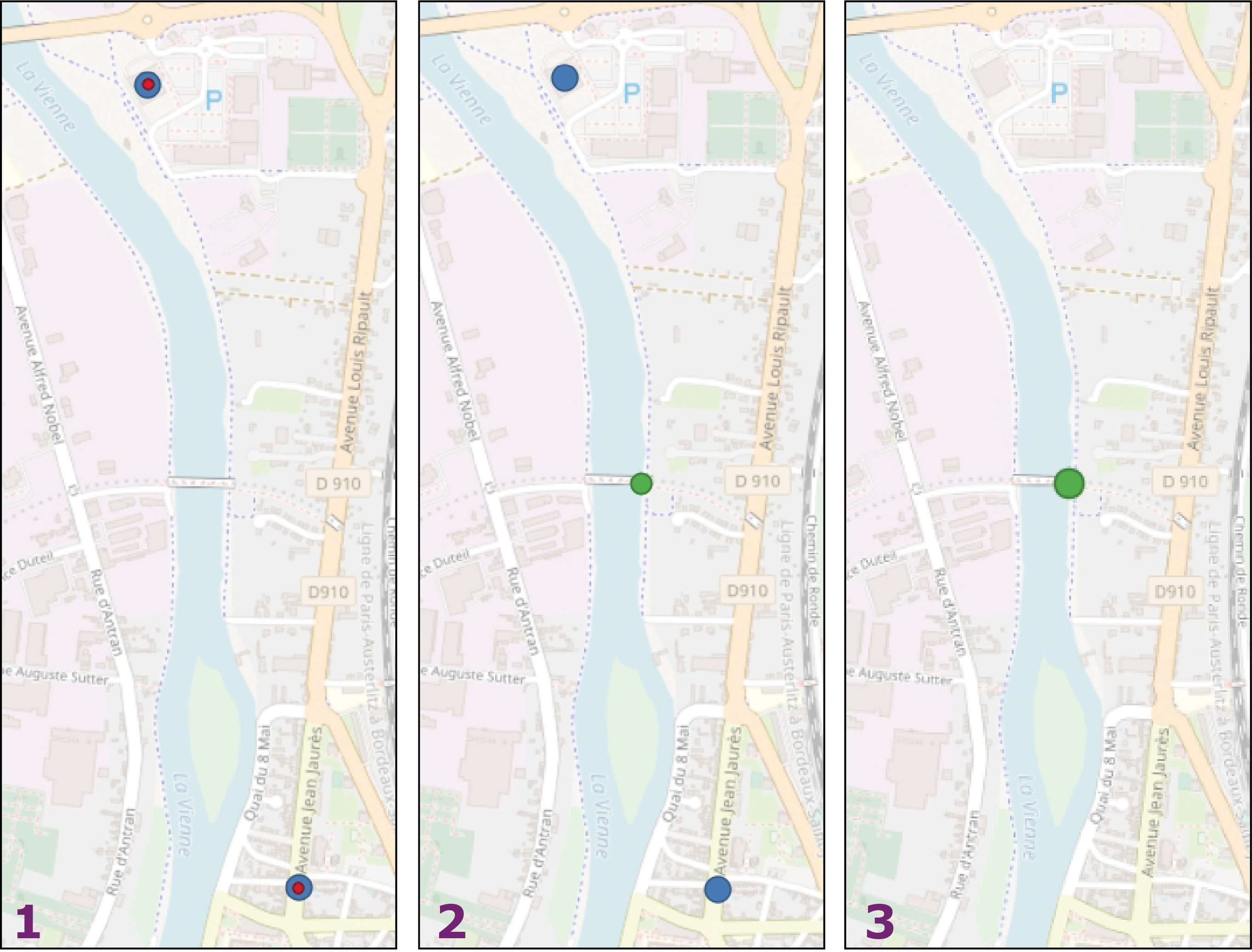
- Requête d'affichage sur la couche matricielle (Properties/Source/Query Builder).
"Distance" <= 1700
- Récupération des centroïdes des entités multipoints restantes (Vector/Geometry Tools/Centroids).
- Suppression des doublons géométriques des centroïdes (Processing Toolbox/Delete Duplicate geometries). En effet la couche matricielle ayant des doublons géométriques, nos centroïdes sont eux aussi en doublon.
- Sélection spatiale des magasins à supprimer en les intersectant avec la couche matricielle, outil Vectors/Research Tools/Select By Location. Mode Editing sur la couche des magasins et suppression de la sélection. La couche matricielle est à présent inutile, vous pouvez la supprimer.
Virtual Layers et requête UNION
Bien, il ne nous reste plus qu'à fusionner nos magasins restants avec les centroîdes extraits.
Cependant si vous examinez les données attributaires des 2 couches, vous y verrez de notables différences dans leur structure. Ainsi si l'outil Merge Vector Layers pourrait parfaitement fusionner les géométries, il nous produira 2 champs différents pour nos différents identifiants, que bien sûr nous souhaitons conserver de façon ordonnée.
Nous allons donc plutôt gérer cette fusion en SQL, avec une requête UNION, dans Database/DB Manager/Virtual Layers/Project Layers. Ici, sélectionnez une couche, n'importe laquelle, afin de faire apparaître le bouton SQL Window, ouvez la fenêtre SQL. Ici, dans l'onglet Query, nous allons pouvoir taper notre propre SQL.
Commencez par faire quelques requêtes de sélection simple, pour vous entrainez.
SELECT id, geometry FROM magasins
Observez que nous sommes capables d'appeler un champ pourtant invisible dans les données attributaire : la géométrie !
En effet à la manière de Postgres, les Virtual Layers peuvent requêter les géométries. Nous ferons d'ailleurs plus tard un peu de SQL spatial.
Mais pour l'instant, la requête UNION :
SELECT id, geometry FROM magasins UNION SELECT InputId, geometry FROM magasins
Maintenant nos identifiants se superposent parfaitement, bien sûr nous n'oublions pas d'appeler les géométries. Exportez-en une couche (option Load as new layer).
Enfin, le 27 décembre 2020, nous identifions 300 et quelques magasins Décathlon dédoublonnés dans les données OSM.
Exportez-en un shape ici nommé decathlon_france, c'est à partir de lui que nous travaillerons. En effet la couche issue des Virtual Layers est une requête, si plus tard vous supprimez les couches qui la constituent, la requête sera invalide.
Normalisez les id (en enlevant les ways, nodes et autre slashs, et en préfixant les valeurs par la lettre d. En effet nous utiliserons ensuite les identifiants pour nommer des fichiers, et il n'est jamais bon de commencer le nom d'un fichier par un chiffre. Dans le Field Calculator de la couche :
REPLACE (id, 'way/', 'd') ...
SQL spatial
Allez hop on va essayer de se faire la totale en SQL spatial :
-- IDENTIFIER LES POINTS PROCHES DE 1700 MÈTRES SELECT DecathlonFr_a.id AS point_id, DecathlonFr_a.geometry AS geometry, COUNT(DecathlonFr_b.id) - 1 AS nbre_voisin FROM DecathlonFr AS DecathlonFr_a JOIN DecathlonFr AS DecathlonFr_b ON ST_DISTANCE(DecathlonFr_a.geometry, DecathlonFr_b.geometry) <= 1700 -- ON ST_DWITHIN(DecathlonFr_a.geometry, DecathlonFr_b.geometry, 1700) GROUP BY DecathlonFr_a.id, DecathlonFr_a.geometry HAVING nbre_voisin > 0 ;
-- GROUPER LES DOUBLONS EN MULTIPOINTS WITH voisinage AS ( SELECT DecathlonFr_a.id AS id, DecathlonFr_b.geometry AS geometry FROM DecathlonFr AS DecathlonFr_a JOIN DecathlonFr AS DecathlonFr_b ON ST_DISTANCE(DecathlonFr_a.geometry, DecathlonFr_b.geometry) <= 1700 ), GrouperEnMulti AS ( SELECT id, ST_COLLECT(geometry) AS geometry, COUNT(geometry) AS nbre_voisin FROM voisinage GROUP BY id ) SELECT id, geometry FROM GrouperEnMulti WHERE nbre_voisin > 1 ;
-- EXTRAIRE LES CENTROÏDES DÉDOUBLONNÉS DES MULTIPOINTS WITH voisinage AS ( SELECT DecathlonFr_a.id AS id, DecathlonFr_b.geometry AS geometry FROM DecathlonFr AS DecathlonFr_a JOIN DecathlonFr AS DecathlonFr_b ON ST_DISTANCE(DecathlonFr_a.geometry, DecathlonFr_b.geometry) <= 1700 ), GrouperEnMulti AS ( SELECT id, ST_COLLECT(geometry) AS geometry, COUNT(geometry) AS nbre_voisin FROM voisinage GROUP BY id ) SELECT MIN(id) AS id, ST_CENTROID(geometry) AS geometry FROM GrouperEnMulti GROUP BY ST_CENTROID(geometry) HAVING nbre_voisin > 1 ;
-- LES NON-DOUBLONS WITH uniques AS ( SELECT id, geometry FROM DecathlonFr WHERE id NOT IN ( SELECT DecathlonFr_a.id FROM DecathlonFr AS DecathlonFr_a JOIN DecathlonFr AS DecathlonFr_b ON ST_DISTANCE(DecathlonFr_a.geometry, DecathlonFr_b.geometry) <= 1700 GROUP BY DecathlonFr_a.id, DecathlonFr_a.geometry HAVING COUNT(DecathlonFr_b.id)-1 > 0 )), -- LA MATRICE DE DISTANCE voisinage AS ( SELECT DecathlonFr_a.id AS id, DecathlonFr_b.geometry AS geometry FROM DecathlonFr AS DecathlonFr_a JOIN DecathlonFr AS DecathlonFr_b ON ST_DISTANCE(DecathlonFr_a.geometry, DecathlonFr_b.geometry) <= 1700 ), -- GROUPEMENT EN MULTIPOINTS GrouperEnMulti AS ( SELECT id, ST_COLLECT(geometry) AS geometry, COUNT(geometry) AS nbre_voisin FROM voisinage GROUP BY id ) -- LES CENTROÏDES DÉDOUBLONNÉS DES MULTIPOINTS SELECT MIN(id) AS id, ST_CENTROID(geometry) AS geometry FROM GrouperEnMulti GROUP BY ST_CENTROID(geometry) HAVING nbre_voisin > 1 -- AJOUT DES NON-DOUBLONS UNION SELECT id, geometry FROM uniques ;
Zones isochrones
 Rendez-vous sur https://openrouteservice.org/ et créez-vous un compte afin de récupérer une clé d'API (le token).
Rendez-vous sur https://openrouteservice.org/ et créez-vous un compte afin de récupérer une clé d'API (le token).
Il s'agit du service associé au plugin ORS Tools, que vous pouvez aussi installer afin de faire quelques tests.
Limitations
Mais le plugin est bridé à 500 zones isochrones par jour et surtout, à des batchs de 5 zones par traitement et 60 zones par minute. Or nous avons 300 et quelques zones isochrones à créer...
Nous allons essayer d'outrepasser ces limites en créant nos zones isochrones dans une boucle Python.
Construction d'un code de création d'une seule zone isochrone
Rendez-vous ici (une fois connecté au service) pour paramétrer la création d'une zone isochrone de test, la visualiser et en extraire son code Python. Utilisez les coordonnées du magasin de Cergy (2.0495375241349554, 49.05473127094994) afin de vérifier que vos paramètres sont bons.
Exemple (mais préfèrez le code que vous donnera le bac à sable de la documentation officielle). Et utilisez votre propre clé d'API (YOUR-API-KEY) :
import os from pathlib import Path import requests repertoireTravail = Path('C:\\Users\\georg\\Downloads\\') fichierGeoJson = os.path.join(repertoireTravail, 'myfile.geojson') if os.path.isdir(repertoireTravail): body = {"locations":[[2.0495375241349554,49.05473127094994]],"range":[900]} headers = {'Accept': 'application/json, application/geo+json, application/gpx+xml, img/png; charset=utf-8', 'Authorization': 'YOUR-API-KEY', 'Content-Type': 'application/json; charset=utf-8' } call = requests.post('https://api.openrouteservice.org/v2/isochrones/driving-car', json=body, headers=headers) # print(call.status_code, call.reason) # print(call.text) with open(fichierGeoJson, 'w', encoding='utf-8') as outfile: outfile.write(call.text) iface.addVectorLayer(fichierGeoJson, 'Isochrone', 'ogr') else: print('Le répertoire est absent !')
Exécutez ce code dans la console Python de QGIS. Le dernier print vous renvoie un GEOJSON (sous forme textuelle pour l'instant).
Vous avez déjà visualisé votre zone isochrone dans la cartographie d'ORS, mais vérifiez que le GEOJSON généré par le code dans QGIS est lui-même valide (en le copiant-collant dans l'outil geojson.io, ou en l'enregistrant puis en l'ouvrant dans QGIS).
Observez les coordonnées que nous utilisons dans le code : elles sont en 4326 (WGS84).
Affichage sous QGIS
Si tout va bien, commentez les print et ajoutez à la suite de votre code les lignes suivantes pour afficher le GEOJSON dans QGIS (en modifiant les chemins) :
with open('C:/Users/Georges/Downloads/myfile.geoson', 'w', encoding='utf-8') as outfile: outfile.write(call.text) iface.addVectorLayer('C:/Users/Georges/Downloads/myfile.geoson', 'Isochrone', 'ogr')
Exécutez l'ensemble du code dans la console Python de QGIS. La zone isochrone créé avec Python apparaît.
Itération
Bien, nous savons créer une zone isochrone dans QGIS avec Python, mais il nous en faut 300 et quelques !
Nous allons donc devoir itérer à travers la couche de points pour créer les zones isochrones correspondantes à partir de leur coordonnées en 4326. Nous ajoutons donc une alerte sur la projection de la couche (if...).
Pour nos tests, nous ne travaillerons que sur 3 points (limit = 3).
import requests mylayer = QgsProject.instance().mapLayersByName("decathlon_france")[0] layerProj = mylayer.crs() limit = 3 i = 0 for feat in mylayer.getFeatures(): id_mag = feat['id'] geom = feat.geometry() i += 1 if i > limit: break print('\nMagasin ' + str(id_mag) + ' (itération ' + str(i) + ')') print('X : ' + str(geom.asPoint().x())) print('Y : ' + str(geom.asPoint().y())) if '4326' not in str(layerProj): print('\nATTENTION : projection différente de 4326 :') else: print('\nOK : la couche est en 4326 :') print(str(layerProj) + '\n')
Reprojection
Si besoin est, nous allons utilisé ce code ci-dessous pour :
- reprojeter notre couche
- l'enregistrer dans un autre shape suffixé "4326"
- fermer la couche d'origine
- ouvrir la nouvelle couche en la nommant de l'exacte même façon que la couche originale. Ainsi nos autres codes fonctionneront de l'exacte même façon.
project = QgsProject.instance() mylayer = QgsProject.instance().mapLayersByName("decathlon_france")[0] mylayer4326 = 'C:/Users/georg/Downloads/decathlon_france4326.shp' processing.run("native:reprojectlayer", { 'INPUT':mylayer, 'TARGET_CRS':QgsCoordinateReferenceSystem('EPSG:4326'), 'CONVERT_CURVED_GEOMETRIES':False, 'OPERATION':'+proj=pipeline +step +inv +proj=lcc +lat_0=46.5 +lon_0=3 +lat_1=49 +lat_2=44 +x_0=700000 +y_0=6600000 +ellps=GRS80 +step +proj=unitconvert +xy_in=rad +xy_out=deg', 'OUTPUT':mylayer4326 }) project.addMapLayer(mylayer) project.removeAllMapLayers() mylayerOpen = QgsVectorLayer(mylayer4326, 'decathlon_france', 'ogr') project.addMapLayer(mylayerOpen)
Marquer les magasins traités
Bien, maintenant il s'agit de marquer les magasins dont la zone a déjà été créée. Car pour contourner les limitations de l'API, et pouvoir relancer notre code à souhait, il nous faudra limiter la boucle à quelques dizaines de points, et marquer les magasins dont la zone a déjà été créée. Ainsi nous n'aurons qu'à ré-exécuter le code plusieurs fois d'affilé pour générer nos 300 et quelques zones isochrones. Attention à la limite de 500 zones par jour, qui elle ne pourra pas être dépassée.
Ajoutez un champ iso dans votre couche de points de test, en integer, à 0. Nous le faisons passer à 1 à chaque zone isochrone créée, et ajoutons une condition pour ne passer que sur les magasins dont la zone n'a pas encore été créée :
with edit(mylayer): for feat in mylayer.getFeatures(): if feat['iso'] == 0: id_mag = feat['id'] geom = feat.geometry() i += 1 if i > limit: break feat['iso'] = 1 mylayer.updateFeature(feat) print(id_mag, geom.asPoint().x(), geom.asPoint().y(), i)
Maintenant, à la suite de la boucle, la zone isochrone, où nous remplaçons les coordonnées en dur par nos géométries, avec l'id des magasins en nom de fichier :
body = {"locations":[[geom.asPoint().x(), geom.asPoint().y()]],"range":[900],"attributes":["area","reachfactor","total_pop"],"range_type":"time"} headers = { 'Accept': 'application/json, application/geo+json, application/gpx+xml, img/png; charset=utf-8', 'Authorization': 'YOUR-API-KEY', 'Content-Type': 'application/json; charset=utf-8' } call = requests.post('https://api.openrouteservice.org/v2/isochrones/driving-car', json=body, headers=headers) #print(call.status_code, call.reason) #print(call.text) with open('C:/Users/Georges/Downloads/CoursQGIS/data/isochrones/'+id_mag+'.geoson', 'w', encoding='utf-8') as outfile: outfile.write(call.text) iface.addVectorLayer('C:/Users/Georges/Downloads/CoursQGIS/data/isochrones/'+id_mag+'.geoson', id_mag, 'ogr')
Mais nous n'avons aucun attribut pour identifier les zones isochrones par magasin. Et nous en aurons besoin par la suite.
Nous ajoutons donc un champ dans le fichier GEOJSON, que nous remplissons avec l'id des magasins.
my_geojson = QgsProject.instance().mapLayersByName(id_mag)[0] pr = my_geojson.dataProvider() pr.addAttributes([QgsField("id_mag", QVariant.String)]) my_geojson.updateFields() with edit(my_geojson): for feature in my_geojson.getFeatures(): feature['id_mag'] = id_mag my_geojson.updateFeature(feature)
OK. Testez le code sur votre extraction de 10 magasins, si cela fonctionne, vous n'avez plus qu'à remplacer la variable mylayer et à augmenter la limit (n'oubliez pas de supprimer les zones précédemment apparues, à la fois dans QGIS mais aussi les fichiers GEOJSON dans votre machine, et de créer le champ iso dans la couche de vos magasins).
Code complet
import requests mylayer = QgsProject.instance().mapLayersByName("decathlon_france")[0] limit = 20 i = 0 with edit(mylayer): for feat in mylayer.getFeatures(): if feat['iso'] == 0: id_mag = feat['id'] geom = feat.geometry() i += 1 if i > limit: break feat['iso'] = 1 mylayer.updateFeature(feat) # print(id_mag, geom.asPoint().x(), geom.asPoint().y(), i) # ZONE ISOCHRONE body = {"locations":[[geom.asPoint().x(), geom.asPoint().y()]],"range":[900],"attributes":["area","reachfactor","total_pop"],"range_type":"time"} headers = { 'Accept': 'application/json, application/geo+json, application/gpx+xml, img/png; charset=utf-8', 'Authorization': 'YOUR-API-KEY', 'Content-Type': 'application/json; charset=utf-8' } call = requests.post('https://api.openrouteservice.org/v2/isochrones/driving-car', json=body, headers=headers) #print(call.status_code, call.reason) #print(call.text) with open('C:/Users/Georges/Downloads/CoursQGIS/data/isochrones/'+id_mag+'.geoson', 'w', encoding='utf-8') as outfile: outfile.write(call.text) iface.addVectorLayer('C:/Users/Georges/Downloads/CoursQGIS/data/isochrones/'+id_mag+'.geoson', id_mag, 'ogr') # AJOUTER ID MAGASIN my_geojson = QgsProject.instance().mapLayersByName(id_mag)[0] pr = my_geojson.dataProvider() pr.addAttributes([QgsField("id_mag", QVariant.String)]) my_geojson.updateFields() with edit(my_geojson): for feature in my_geojson.getFeatures(): feature['id_mag'] = id_mag my_geojson.updateFeature(feature)
Hop ! Vous obtenez 300 et quelques zones isochrones à 15 minutes en voiture pour atteindre un magasin Décathlon ! Merci aux contributeurs OpenStreetMap et à l'université d'Heidelberg !
IGN
Petite parenthèse, un exemple d'utilisation de l'API isochrones de l'IGN !
Merci aux étudiants du master de géomatique CYU (Cergy) !
import requests import time from qgis.core import (QgsProject, QgsVectorLayer, QgsFeature, QgsGeometry, QgsField, QgsPointXY, QgsWkbTypes, QgsCoordinateTransform, QgsCoordinateReferenceSystem) from PyQt5.QtCore import QVariant base_url = "https://data.geopf.fr/navigation/isochrone" # Temps de déplacement en minutes tempsDeplacement = 15 # Direction de déplacement directionDeplacement = "arrival" # Sélectionne la couche active dans QGIS input_layer = iface.activeLayer() if not input_layer: raise Exception("Aucune couche active sélectionnée") if input_layer.geometryType() != QgsWkbTypes.PointGeometry: raise Exception("La couche doit contenir des POINTS") source_crs = input_layer.crs() target_crs = QgsCoordinateReferenceSystem("EPSG:4326") transform = None if source_crs != target_crs: transform = QgsCoordinateTransform(source_crs, target_crs, QgsProject.instance()) print("Reprojection activée :", source_crs.authid(), "EPSG:4326") nomCouche = "Isochrones" + " " + str(tempsDeplacement) + " " + directionDeplacement output_layer = QgsVectorLayer("Polygon?crs=EPSG:4326", nomCouche, "memory") provider = output_layer.dataProvider() provider.addAttributes([ QgsField("id_point", QVariant.Int), QgsField("minutes", QVariant.Int), QgsField("direction", QVariant.String) ]) output_layer.updateFields() total = input_layer.featureCount() batch = [] # ajout toutes les 50 features batch_size = 50 for i, feat in enumerate(input_layer.getFeatures()): geom = feat.geometry() if not geom or geom.isEmpty(): continue if geom.isMultipart(): point = geom.asMultiPoint()[0] else: point = geom.asPoint() if transform: point = transform.transform(point) lon = point.x() lat = point.y() params = { "resource": "bdtopo-valhalla", "profile": "car", "costing": "auto", "costType": "time", "costValue": tempsDeplacement, "direction": directionDeplacement, "point": f"{lon},{lat}", "geometryFormat": "geojson", "timeUnit": "minute" } try: response = requests.get(base_url, params=params, timeout=30) response.raise_for_status() data = response.json() coords = data["geometry"]["coordinates"][0] polygon = QgsGeometry.fromPolygonXY( [[QgsPointXY(x, y) for x, y in coords]] ) new_feat = QgsFeature() new_feat.setGeometry(polygon) new_feat.setAttributes([i, tempsDeplacement, directionDeplacement]) batch.append(new_feat) # Ajout par paquet pour éviter surcharge mémoire if len(batch) >= batch_size: provider.addFeatures(batch) batch = [] print(f"{i+1}/{total} traité") # anti rate-limit (2 req/sec max) time.sleep(0.5) except Exception as e: print(f"Erreur point {i+1} :", e) # Ajouter le reste if batch: provider.addFeatures(batch) output_layer.updateExtents() QgsProject.instance().addMapLayer(output_layer) print("Traitement terminé")
Zones statistiques
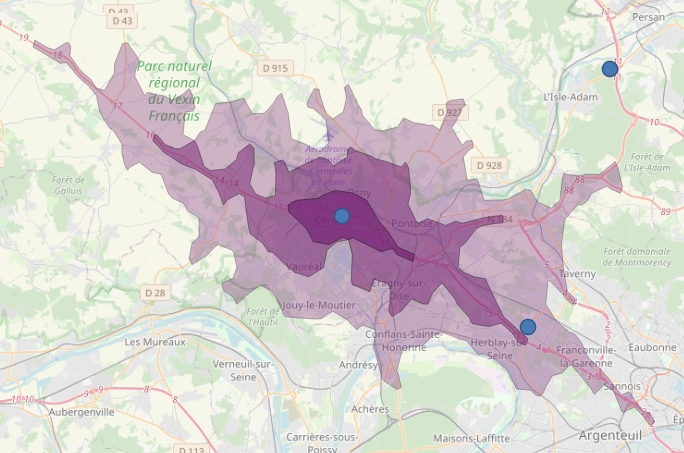
Nous allons maintenant rapatrier les données statistiques infra-communales (les IRIS français) de l'INSEE sur nos zones isochrones.
Pour cela il nous faudra d'abord ramener les IRIS dans nos zones isochrones. Téléchargez le shape des IRIS français sur le site de L'IGN.
Fusion
Avant de nous attaquer au rapatriement des données IGN puis INSEE, fusionnez d'abord vos 300 et quelques zones isochrones dans un seul shape (Vector/Data Management Tools/Merge Vector Layers).
Une fois fait, vous pouvez supprimer vos 300 et quelques GEOJSON de votre projet QGIS. Supprimez également les champs inutiles de votre shape de sortie, nous ne garderons que l'id_mag bien sûr, mais aussi les champs area et total_pop (fournis par le service ORS), afin de faire quelques vérifications plus tard.
 Découpe
Découpe
Découpez maintenant la couche des IRIS sur vos polygones isochroniques. Attention, nous devons conserver les doublons dans le cas des IRIS appartenant à plusieurs zones isochrones !
Utilisez donc l'outil Vector/Geoprocessing Tools/Intersection, vérifiez la présence de vos IRIS en doublons dans la table attributaire, mais aussi en faisant quelques tests de sélection sur votre couche de sortie à partir de l'id des magasins (en jouant sur la transparence des couches, la ville de Rennes est idéale pour ces vérifications).
PS : Plus tard, nous verrons comment automatiser ce type de sélection en Python. Ce sera très pratique pour visualiser proprement des zones isochrones qui se superposent.
Exportez un shape de votre couche de sortie, ici nommé iso_iris.
Rationalisation
Bien, disposant du CODE_IRIS, nous pourrions d'ores-et-déjà ramener les informations statistiques infra-communales de l'INSEE sur notre nouveau shape.
Cependant tel quel, la pertinence géographique serait discutable car dans bien des cas seules des portions très congrues d'IRIS ont été découpées. Or si un grand IRIS abrite 5000 personnes, mais que seuls quelques mètres carrés appartiennent à une zone isochrone, nous ne pouvons pas compter ces 5000 personnes dans notre zone.
Nous allons donc calculer un pourcentage surfacique pour chacun des IRIS compris dans nos zones isochrones. À terme il fournira un quotient nous permettant d'extraire des valeurs statistiques supposément plus fiables.
- Commençons par calculer la surface de nos portions d'IRIS compris dans nos zones isochrones, dans un nouveau champ nommé part, avec le Field Calculator, fonction
$area. Soyons généreux sur ses décimales, car certaines portions d'IRIS sont particulièrement petites. Enregistrez vos modifications. - Faisons-en de même avec les IRIS complets, dans un champ nommé area. Enregistrez.
- Jointure depuis la couche iso_iris vers les IRIS, pour ramener le champ area nouvellement créé. Bien entendu nous utiliserons le champ CODE_IRIS.
- Calcul du rapport entre nos 2 aires dans un nouveau champ nommé quotient. Enregistrement.
"part" / "iris_area"
Bien, nous pouvons maintenant supprimer la jointure (ou directement la couche des IRIS) ainsi que le champ part, nous disposons de notre quotient de rationalisation des futures données INSEE que nous allons rapatrier.
Données INSEE
Télécharger les bases INSEE suivantes, dans leur version la plus récente bien sûr :
- Nombre d'équipements et de services dans le domaine du commerce
- Couples - Familles - Ménages
- Activité des résidents
Nettoyez le 1er onglet des fichiers pour une utilisation en tant que tableau de données puis importez-les dans QGIS.
Examinez les méta-données et joignez à votre couche iso_iris la population des IRIS (champ C17_PMEN), le nombre d'actifs se déplaçant principalement en voiture (champ C17_ACTOCC15P_VOIT) et le nombre de magasins d'articles de sports et de loisirs (champ NB_B307).
Modifiez les préfixes utilisés par les jointures pour avoir des noms de champs lisibles.
Astuce : si le projet QGIS supporte mal le poids des fichiers, supprimez les champs inutiles et enregistrez les fichiers en CSV.
À présent, ne reste plus qu'à calculer les valeurs virtuelles de ces champs en fonction de notre quotient. Profitez-en pour les nommer de façon plus lisible (avec de nouveaux champs pop, a_voiture et m_sport) et pour éliminer les décimales.
Dans le Field Calculator :
"iris_C17_PMEN" * "quotient" ...
Et de supprimer les jointures, devenues inutiles.
Pour le calcul du nombre de magasins d'articles de sports et de loisirs par portion d'IRIS, vous pouvez remplacer les valeurs NULL par 0.
CASE WHEN "m_sport" IS NULL THEN 0 ELSE "m_sport" END
Sélection automatique
Pour le plaisir d'y voir clair, créons une fonction pour sélectionner nos portions d'IRIS appartenant à la zone isochrone d'un magasin après sélection d'un magasin.
layer_selected = QgsProject.instance().mapLayersByName("decathlon_france")[0] layer_to_select = QgsProject.instance().mapLayersByName("iso_iris")[0] def SelectionAuto(): selected_features = layer_selected.selectedFeatures() for i in selected_features: attrs = i.__geo_interface__ id_mag = i['id'] #print (id_mag) myselect = layer_to_select.getFeatures( QgsFeatureRequest().setFilterExpression ( u'"id_mag" = \'%s\'' % id_mag ) ) layer_to_select.selectByIds( [ f.id() for f in myselect ] ) #iface.mapCanvas().zoomToSelected(layer_to_select) layer_selected.selectionChanged.connect(SelectionAuto)
Vous pouvez creuser cette possibilité ici : Sélection intelligente.
Synthése des données
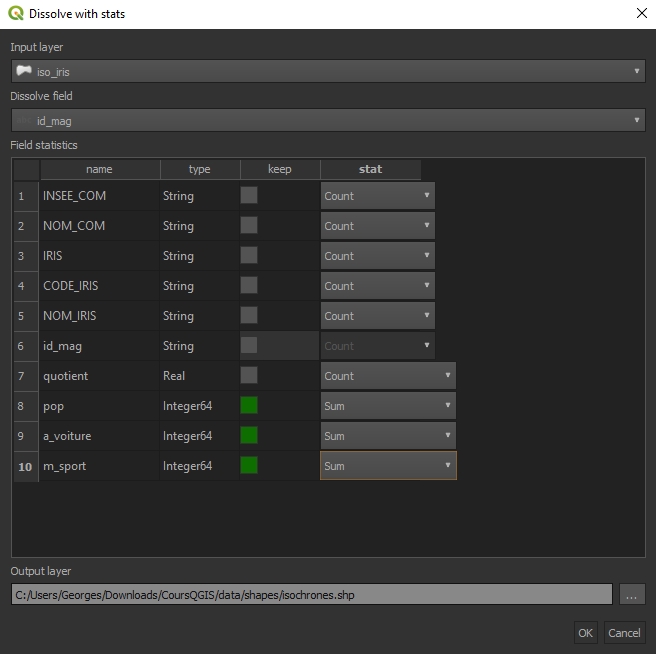 À présent nous pouvons fusionner (regrouper) nos portions d'IRIS en sommant nos valeurs virtuelles caractéristiques (l'équivalent d'une requête de regroupement).
À présent nous pouvons fusionner (regrouper) nos portions d'IRIS en sommant nos valeurs virtuelles caractéristiques (l'équivalent d'une requête de regroupement).
L'excellent plugin Dissolve With Stats est fait pour ça. Nous utiliserons le champ identifiant des magasins pour le regroupement, et nous passerons des champs inutiles.
N'hésitez pas à faire quelques vérifications grâce à la sélection automatique précédente (en comptant le nombre d'autres magasins d'article de sport dans une zone). Nous disposons maintenant de la population, du nombre d'actifs se déplaçant principalement en voiture et du nombre de magasins d'articles de sports et de loisirs pour chaque zone isochrone.
Vous avez compris l'intérêt de ces zones, auxquelles nous pourrions ajouter un indicateur plus qualitatif, comme celui calculé ici.
Bien sûr ces zones isochrones n'ont qu'une valeur contextuelle. Dans un cadre professionnel, ou selon la demande (le contexte), il faudrait les enrichir des horaires utilisés, d'enquêtes de terrain et de vérifications cas par cas.
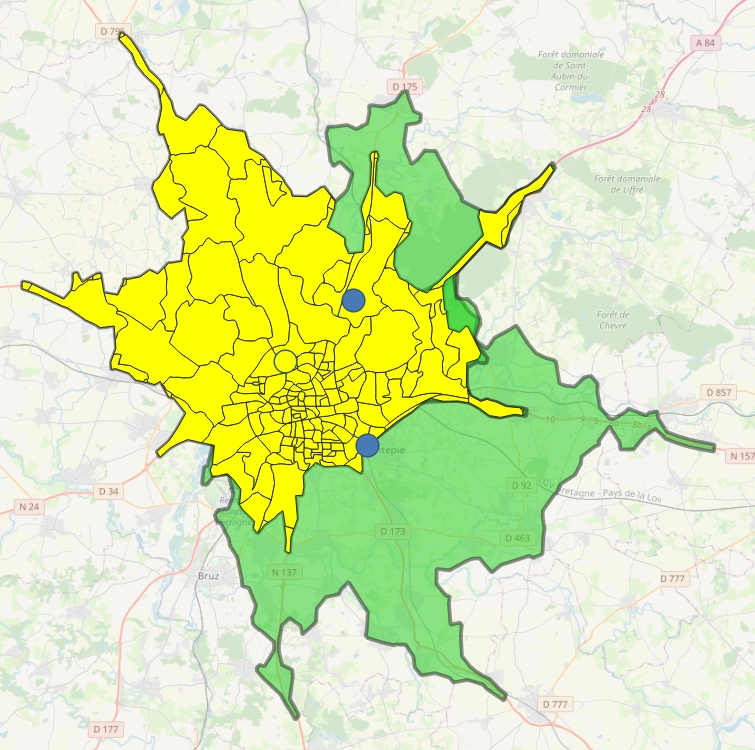
Cannibalisation
Bien sûr visuellement nous avons déjà une bonne idée des cannibalisations à l'œuvre, mais il est intéressant d'être capable de les lister.
Identifions-les grâce aux Virtal Layers de QGIS et au SQL spatial à notre disposition : outil Database/DB Manager/Virtal Layers/isochrones. .
D'abord un peu de SQL très simple pour lister les identifiants des magasins de nos 300 et quelques zones isochrones, en guise d'entraînement.
SELECT id_mag FROM isochrones
Testons maintenant la fonction ST_INTERSECTS qui nous permet d'intersecter les géométries (du SQL spatial donc) :
SELECT id_mag FROM isochrones WHERE ST_INTERSECTS(isochrones.geometry,isochrones.geometry)
Humm... Chaque zone s'intersecte elle-même, et ne récupère même pas les intersections croisées (seulement 300 et quelques résultats).
Ajoutons donc une jointure réflexive, pour croiser notre table sur elle-même. En même temps, nous ajouterons des alias à nos tables, afin d'y voir clair dans notre jointure.
SELECT a.id_mag AS a_id, b.id_mag AS b_id FROM isochrones AS a, isochrones AS b WHERE ST_INTERSECTS(a.geometry,b.geometry)
Là oui ! En revanche l'intersection conserve encore les zones s'intersectant elles-mêmes. Arrrggh !
Ajoutons donc une comparaison par identifiant pour exclure les zones qui s'intersectent elles-mêmes.
SELECT a.id_mag AS a_id, b.id_mag AS b_id FROM isochrones AS a, isochrones AS b WHERE ST_INTERSECTS(a.geometry,b.geometry) AND a_id <> b_id
Nous commençons à arriver à quelque chose. Observez vos résultats et faites une sélection de quelques magasins pour vérifier. Exemple, dans Select By Expression :
"id_mag" = 'd186766319' OR "id_mag" = 'd71408480' OR "id_mag" = 'd220108727'
Il semble que nous soyons parvenus à nos fins. Mais chaque zone intersectante apparaît 1 fois par magasin intersecté, c'est peu lisible.
Mettons notre requête d'intersection dans une sous-requête, et ajoutons une requête de regroupement pour compter les zones intersectantes par magasins.
SELECT a_id, GROUP_CONCAT(b_id) AS b_id FROM (SELECT a.id_mag AS a_id, b.id_mag AS b_id FROM isochrones AS a, isochrones AS b WHERE ST_INTERSECTS(a.geometry,b.geometry) AND a_id <> b_id) GROUP BY a_id
C'est mieux. Nous pouvons encore aussi ajouter un comptage des magasins cannibalisés par un autre :
SELECT a_id, GROUP_CONCAT(b_id) AS b_id, COUNT(b_id) AS cannibalized FROM (SELECT a.id_mag AS a_id, b.id_mag AS b_id FROM isochrones AS a, isochrones AS b WHERE ST_INTERSECTS(a.geometry,b.geometry) AND a_id <> b_id) GROUP BY a_id
Enfin, vérifions que chaque magasin intersecté possède sa propre ligne :
SELECT a_id, GROUP_CONCAT(b_id) AS b_id, COUNT(b_id) AS cannibalized FROM (SELECT a.id_mag AS a_id, b.id_mag AS b_id FROM isochrones AS a, isochrones AS b WHERE ST_INTERSECTS(a.geometry,b.geometry) AND a_id <> b_id) GROUP BY a_id HAVING a_id IN ('d100939496', 'd196253319', 'd8191733594')
C'est bien le cas (notez le HAVING, qui vient remplacer le WHERE dans les requêtes de regroupement GROUP BY).
Nous pouvons donc dire que sur nos 300 et quelques magasins, à partir de zones isochrones en voiture de 15 minutes, nous avons 200 magasins en proie à une cannibalisation, et pour chacun le décompte des magasins impliqués.
Nous pourrions aussi nous amuser à compter les cas de cannibalisation, en regroupant dans une seule ligne les magasins cannibalisés entre eux. Pour cela il suffirait de fusionner les zones s'intersectant (en conservant les doublons : une zone intersectant 2 zones qui elles-mêmes ne s'intersectent pas, devra être liée à 2 entités fusionnées distinctes). Puis d'intersecter les magasins appartenant à ces entités de fusion. Tout cela pourrait être fait en SQL spatial, je vous laisse vous amuser...
Bien sûr la notion de cannibalisation est contextuelle, et devrait être enrichie des zones de chalandise cumulées, du peuplement territorial, des densités de population, de la taille des magasins, d'enquêtes de terrain... Mais c'est un bon début !
| [Les zones isochrones fusionnées] | 979 Ko | |
| [Les fichiers GEOJSON des zones isochrones] | 786 Ko | |
| [key=shop ; value=sport ; in=France] | 0 Ko |