Data management with Python, Pandas, Geopandas, Sqlachemy, Matplotlib and Openpyxl
- Détails
- 140361
![]() Pandas is an excellent Python librarie to manage data. Matplotlib allows to create advanced charts and Openpyxl is very usefull to read/write Excel files. These 3 tools, combined with other classic Python features, allow to do data analysis and engineering.
Pandas is an excellent Python librarie to manage data. Matplotlib allows to create advanced charts and Openpyxl is very usefull to read/write Excel files. These 3 tools, combined with other classic Python features, allow to do data analysis and engineering.
Here we will use PyCharm (Community Edition), but it is not mandatory.
First install or check Python and Pip, then the 3 libraries:
pip install pandas pip install matplotlib pip install openpyxl
Data management with Python, Pandas, Geopandas, Sqlachemy, Matplotlib and Openpyxl
Zones isochrones avec QGIS, Python, l'API ORS et les données OSM, IGN et INSEE
- Détails
- 53669
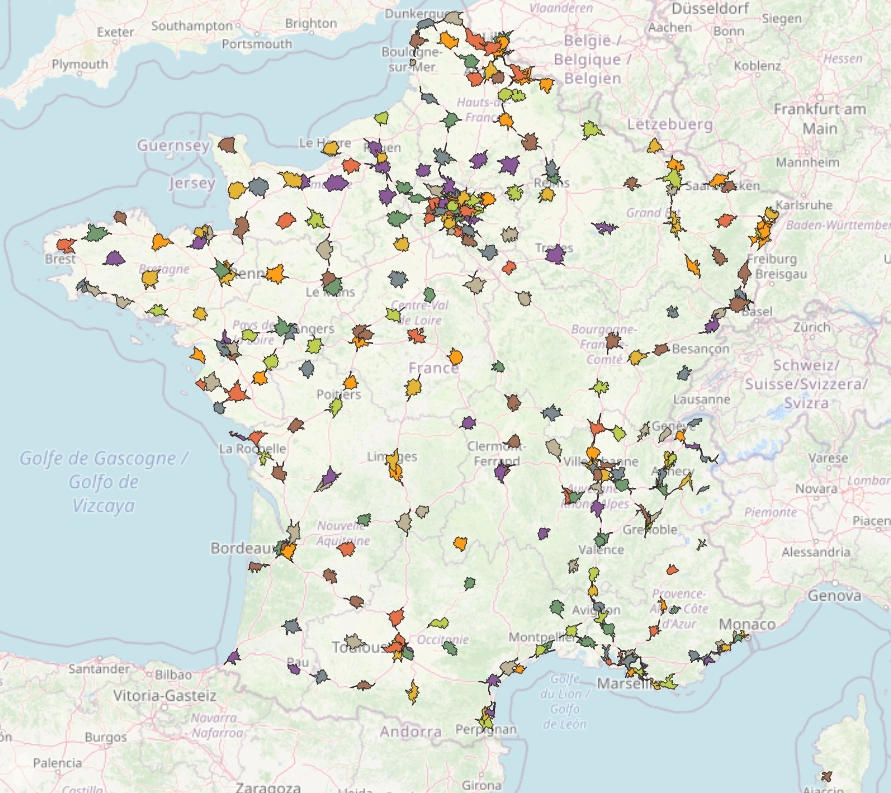 Nous allons calculer les zones isochrones à 15 minutes des magasins Décathlon français, et les coupler avec les données géographiques de l'IGN croisées avec les données statistiques de l'INSEE.
Nous allons calculer les zones isochrones à 15 minutes des magasins Décathlon français, et les coupler avec les données géographiques de l'IGN croisées avec les données statistiques de l'INSEE.
L'ensemble formera de supposées zones de chalandise des magasins, particulièrement pertinentes car couplées avec de vraies zones isochrones. Nous calculerons aussi la cannibalisation des magasins, ainsi que leur proximité avec des équipements sportifs.
Pour ce faire nous n'utiliserons que des données en open-source, l'API d'openrouteservice, le logiciel libre QGIS et peut-être un peu de code Python.
Mots-clefs : géomarketing, IRIS, INSEE, IGN, OSM, SIG, BDD, traitement de données, SQL, zones de chalandise, indicateur, requête de regroupement, zones isochrones, Python
Enseignants responsables : Georges Hinot
Pré-requis : des notions sur QGIS ou autres SIG, des notions sur Excel ou autres tableurs.
Compétences visées : maîtrise théorique et technique des notions de base du géomarketing (zones isochrones, zones de chalandise, indicateurs, jointures et requêtes de regroupement).
Enjeux du cours : rendre autonome les étudiants sur la recherche et l’usage de données autour de problématiques géomarketing, faire « parler » la donnée, créer des indicateurs, veiller à la pertinence des données représentées.
Programme pédagogique : mise en situation autour d'une commande géomarketing impliquant la récupération, le traitement et la représentation de données. Selon l'avancée du cours, nous irons jusqu'à utiliser des fonctionnalités avancées de QGIS (SQL spatial) et Python (création de zones isochrones via une API et customisation du comportement de QGIS).
Le sommaire de droite et la navigation sous le texte vous permettent de vous déplacer dans ce tutoriel.
Zones isochrones avec QGIS, Python, l'API ORS et les données OSM, IGN et INSEE
Installer Postgres et son extension GIS sous Windows
- Détails
- 8450
...et afficher quelques données géographiques sous QGIS
Salut toi ! Prêt à bénéficier de toute la puissance de Postgres ? Tu as bien mis ta ceinture de sécurité ?
Maîtrise tes tremblements, bien compréhensibles face à ce déluge de technologies aux performances abyssales, et prépare-toi à entrer dans un monde nouveau, où l'imagination est la seule limite !
🤖🤟🌐💪🧭🐘
Tutoriel avancé QGIS et Python (PyQGIS)
- Détails
- 137681
 Mots-clefs : interopérabilité Python/QGIS, variable, boucle, fonction, condition, liste, argument, chaîne formatée, fonctions géométriques, création de fichiers, génération de cartes, fonctions cartographiques, fonctions standalone, traitement de données cartographiques, workflow, milieu alpin
Mots-clefs : interopérabilité Python/QGIS, variable, boucle, fonction, condition, liste, argument, chaîne formatée, fonctions géométriques, création de fichiers, génération de cartes, fonctions cartographiques, fonctions standalone, traitement de données cartographiques, workflow, milieu alpin
Enseignant responsable : Georges Hinot
Pré-requis : une bonne connaissance d'un logiciel SIG supportant Python (QGIS ou ArcGIS par exemple) et des problématiques/besoins/enjeux de la géomatique.
Compétences visées : mettre en place un protocole de développement autour d'une problématique géomatique, de la « re-contextualisation du besoin » jusqu'à l'écriture d'un script Python répondant à ce besoin.
Enjeux du cours : rendre les étudiants autonomes dans la création et l'entretien de scripts « automatisants ». Dans ce type de tâche, l’autonomie consiste à savoir interpréter un besoin humain, ré-interpréter ses propres problématiques de programmation et à écrire/chercher/modifier les blocs de code nécessaires.
Programme pédagogique : initiation aux fondamentaux du langage puis mise en situation (générer des cartes à partir de données géographiques). En plus de la simple automatisation des cartographies, le cours nous donnera l'occasion, toujours en Python, d'utiliser des API, de traiter des données et de mettre en place des modes d'affichages customisés sur QGIS. Selon l'avancée du cours, nous pourrons aussi aborder le mode « standalone » permis par le duo QGIS-Python, la création de plugins QGIS et les possibilités de webmapping/analyse/ingénierie de données permises par Python.
PyQGIS
- Détails
- 41445
Some PyQGIS tips, from the most common to the most practical, to learn or optimize your use of QGIS with Python.
Sécurité Joomla
- Détails
- 12728
Les permissions
Les permissions des fichiers et dossiers (CHMOD, abréviation de Change Mode) recommandées sur Joomla (ou d'autres applications PHP) dépendent en partie des hébergeurs.
Un même droit est parfois interprêté différemment selon l'hébergeur (déjà vu), une même application requiert parfois différents droits selon l'hébergeur. Certains serveurs vont automatiquement bloquer certains droits sur certains contenus.
Mais quand un site commence à être mature, il subit de moins en moins de modifications structurelles. On peut alors fermer certaines portes - comme on fermerait l'accès au compteur électrique - et mettre en place une politique des moindres privilèges.
La mise en place d'une politique des moindres privilèges doit être suivie de tests et d'une communication fine avec son hébergeur. Il n'y a rien d'exhautif et rien de parfait, n'hésitez pas à modifier progressivement les permissions vers le bas selon vos propres observations. Il s'agit de fermer au maximum, puis de ne ré-ouvrir que le strict nécessaire.
Page 1 sur 6