Les expressions régulières (regex) sont très pratiques pour standardiser un fichier de données avant import par exemple, récupérer des données, corriger des chaînes particulières, avec des conditions, etc...
Ici quelques astuces propres à mon usage personnel.
L'article est écrit en partant du principe qu'on utilise Notepad++ , sauf quand c'est précisé en rouge (il peut y avoir des différences quand on utilise des regex avec Python par exemple).
Et en parlant de Python, des exemples plus spécifiques d'usage de regex avec Pandas se trouve sur cet autre article.
Marquer des lignes
Si vous recherchez une chaîne particulières dans un fichier - exemple : mailto: - et que vous souhaitiez marquer les lignes concernées, en les faisant débuter par un arobas (@) :
Remplacer :
^(.*)(mailto:)(.*)$
Par :
@$1$2$3
Récupérer uniquement les adresses emails
Astuce récupérée sur https://www.ybierling.com/en/home, grand merci !
Supposons que vous ayez un fichier contenant des adresses emails placées aléatoirement, tantôt sur une seule ligne, tantôt au milieu d'une ligne, tantôt au début, à la fin... C'est peut-être le cas dans votre fichier local de stockage de votre boite mail (Thunderbird par exemple).
Note : Thunderbird sur Windows 10 stocke en ce qui me concerne les messages dans C: \ Users \ Georges \ AppData \ Roaming \ Thunderbird \ Profiles \ 2c2jwgkh.default \ ImapMail \ mail.euromedicom-7.org \ INBOX
Technique de récupération en 3 étape :
PS: Si votre fichier est trop gros, découpez-le avant avec fSplit.exe.
1) Afin de mettre chaque adresses emails sur une seule ligne, remplacez (en mode Expressions régulières) :
(\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}\b)
Par :
\n$1\n
2) Utilisez la même expression régulière pour marquer les lignes avec une adresse email :
Toujours dans la fenêtre Replace, onglet Mark, option Bookmark line, bouton Mark All.
3) Enfin, dans le menu Search/Bookmark, option Remove Unmarked Lines afin de ne conserver que les lignes intéressantes. Hop !
Ou simplement les rechercher
[A-Za-z1-9.-]+@[A-Za-z1-9.-]+
Autres exemples, selon les cas
Chercher la présence de mail dans un champ
[^@]+@[^@]+\.[^@]+
Chercher si la valeur d'un champ correspond strictement à un email
\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b
Ensembles de lignes
Chercher des lignes suivies d'autres lignes particulières
Ici par exemple, des lignes qui commencent par un tiret et sont suivies par une ligne commençant par un espace :
^[-](.*)$\r\n^[ ]
Ou inversement, les lignes commençant par un tiret puis suivies par une ligne vide :
^[-](.*)$\r\n^[ \t]*$\r?\n
Commence par un chiffre
^[0-9]
Commence par une lettre
^[a-z]
Ne commence pas par une lettre
^[^a-z]
Ne commence pas par un chiffre
^[^0-9]
Ne commence pas par un mot
^(?!Mot)
Chercher les lignes qui contiennent plusieurs fois un même caractère
Ici par exemple les lignes qui contiennent au moins deux point-virgules :
^(.*.;.*.;.*)$
Finit par un point
[.]$
Ne contient pas #
^((?!#).)*$
Contient un motif potentiellement suivi d'un autre
Exemple : contient XXX potentiellement (?) suivi d'un espace (/s), suivi de AAA potentiellement suivi d'un tiret.
XXX(\s)?AAA(\\-)?
- Attention : testé sous Python, et non Notepad.
Contient un pourcentage, positif ou négatif, avec ou sans décimal utilisant un point ou une virgule, avec ou sans espace devant le signe pourcentage
(-?\d+[.,]?\d*)\s?%
- Attention : testé sous Python, et non Notepad.
Supprimer des portions inutiles
Exemple dans le cas de liens mailto. Rappelons la forme d'un lien mailto :
<a href="mailto:Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser.">Text</a>
Si vous supprimez tout ce qui vient avant mailto: et tout ce qui vient après le dernier " restant, alors vous ne récupérerez plus que les emails.
Supprimez tout ce qui vient avant :
^(.*)(mailto:)
Supprimez tout ce qui vient après :
(")(.*)$
Pour cette fois supprimer toutes les lignes qui ne contiennent pas la chaîne http, supprimez ces lignes :
^(?!http).*
Remplacement selon chaîne suivie/précédée
Remplacement avec chaîne suivie par une autre et sans toucher à la chaîne qui suit
Vous souhaitez identifier la chaîne RN à chaque fois que celle-ci est directement suivie par un chiffre (exemple : RN6) afin d'ajouter un espace entre RN et le chiffre, et sans supprimer le chiffre bien évidemment.
Utilisez le motif (?=) pour signifier que vous souhaitez repérer sans sélectionner ce qui suit :
RN(?=\d)
Remplacement avec chaîne suivie par une autre, précédée par une autre, et sans toucher...
Pour remplacer les espaces précédés d'un numéro et suivi de " de ", afin de remplacer "6 de Bretagne" par "6 rue de Bretagne" par exemple.
Utilisez le motif \K pour signifier que vous souhaitez repérer sans sélectionner ce qui précède :
(^\d+\K) (?=de )
Et parfois (sous Python), pour sélectionner le point quand séparateur décimal par exemple :
(?<=\d)\.(?=\d)
Supprimer le dernier champ
Si par exemple vous 6 champs séparés par des tabulations :
(^.*\t.*\t.*\t.*\t.*\K)\t.*
Correction de fichiers corrompus par des sauts de lignes intempestifs
Dans le cas d'imports de fichiers text, csv, etc... vers une base de données SQL, les sauts de lignes non-souhaités (souvent issus de champs Notes, des zones de texte, tags <BR>, tabulations ou autre HTML mal interprêtés...) sont très pénibles. Ils peuvent faire échouer les imports ou vous faire perdre du temps. Explorer son fichier sous Notepad est parfois nécessaire.
Nous allons commencer par quelques tests bien utiles pour prendre connaissance d'un fichier, mais dont nous verrons qu'ils sont insuffisants. Nous finirons par une Correction complète en 4 temps .
Chercher les lignes qui ne commencent pas avec tel caractère
Si vos débuts de ligne sont censés commencer par des guillemets double par exemple (champs entourés par ", ce système d'enclosure SQL est très répandu, c'est pourquoi nous l'utilisons ici).
En Mode de recherche Expressions régulières, vous pouvez tester les lignes ne commençant pas avec ces guillemets double ainsi :
^[^"]
Le 1er chapeau signifie en début de ligne. Les crochets délimitent l'ensemble à tester. Le 2nd chapeau, entre crochets, signifie qui n'est pas (une fois inclu dans l'ensemble, dans les crochets). Les guillemets double sont le caractère à tester (à remplacer en fonction de vos besoins).
L'expression régulière ci-dessus vous renverra donc aux lignes ne commençant pas avec des guillemets double, mais en vous sélectionnant aussi le 1er caractère de la ligne. Atention donc aux remplacements sous cette forme.
Une autre méthode est de chercher les sauts de ligne (au lieu du début de ligne), de cette façon :
\n[^"]
L'expression \n signifiant un saut de ligne. Ce qui vous renverra toujours aux lignes ne commençant pas avec des guillemets double, mais toujours en vous sélectionnant 1er caractère de la ligne. Ce n'est donc pas non plus idéal pour des remplacements précis (sauf pour des chaînes de texte redondantes en défaut, en les faisant une-par-une si elles sont peu nombreuses, ou si on les connaît à l'avance).
Chercher les lignes commençant avec un caractère alphanumérique
Dans ce cas précis, une méthode inverse donnerait le même résultat, en recherchant cette fois les lignes commençant avec un caractère alphanumérique (lettres, chiffres et underscore, grâce à l'expression \w). Et donc ne commençant pas par un guillemet double :
\n[\w]
Ou
^[\w]
Mais là encore ce n'est pas idéal pour des corrections précises et sans perte, puisque un remplacement élimine toujours le 1er caractère des lignes corrompues.
Correction complète en 4 temps
Comment donc gérer efficacement ces sauts de lignes ?
Dans notre exemple, nous souhaitons traiter les lignes ne commençant pas avec des guillemets double au sein d'un fichier où les lignes saines commencent avec des guillemets double.
Nous allons procéder en 4 temps :
1) Remplacement de tous les sauts de ligne correctement enclosés et du 1er guillemet double par une chaîne complexe, volontairement choisie pour être totalement absente du fichier :
Rechercher \r\n^["]
Remplacer par xxxxxyzf123456789fzyxxxxx"
Le nombre de lignes de votre fichier va nettement diminuer, et vous allez visualiser sans peine les éventuelles erreurs.
2) Remplacement de tous les sauts de lignes restants (les corrompus) par un espace :
Rechercher \r\n
Remplacer par
L'espace est nécessaire afin de ne pas concaténer les chaînes illogiquement séparées par des sauts de lignes.
Là encore votre fichier maigrit à vue d'œil. Si vous regardez bien les curseurs de Notepad, vous verrez aussi que sa longueur a augmenté.
3) Remplacement de tous les sauts de lignes encore restants (je ne sais expliquer ceux-ci, sans doute une question d'encodage) par un espace également :
Rechercher \n
Remplacer par
Vous n'obtenez alors plus qu'une seule loooonnngue ligne. C'était l'objectif.
4) Parfait, vous n'avez plus qu'à remplacer dans cette ligne unique notre fameuse chaine complexe par des sauts de lignes suivis d'un guillemet.
Tous les sauts de ligne ayant été supprimés, vous serez ainsi sûr de ne rétablir que les sauts de lignes nécessaires au début de chaque enregistrement :
Rechercher xxxxxyzf123456789fzyxxxxx"
Remplacer par \r\n"
La ligne à rallonge reprend la forme d'un fichier standard, mais sans les sauts de lignes non-voulus, bon pour import !
Cumuler des fichiers dans un seul fichier
Cette astuce ne concerne pas directement Notepad, mais elle a toute sa place ici.
Dans le cas où vous avez récupéré une multitude de petites fichiers que vous souhaitez concaténer dans un seul fichier :
1) Assemblez tous ces fichier dans un seul répertoire.
2) Dans ce répertoire, créez un fichier cumul.txt et mettez-y le code suivant :
copy *.txt importfichier.txt
3) Renommez votre fichier cumul.txt en cumul.bat, puis double-cliquez dessus :
Un fichier nommé importfichier.txt va se créer, contenant les données des petites fichiers.
Récupérer une chaîne entre 2 chaines
Exempe, récupérer tout ce qui se trouve entre le signe = et une virgule :
=(.+?),
Séparateur décimal - Remplacer une chaîne entre 2 chiffres inconnus
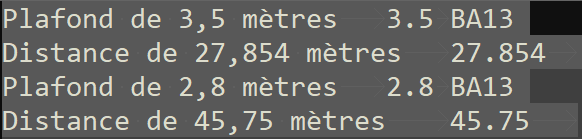
Imaginez un fichier où des virgules servent de séparateur décimal dans des champs textes que vous ne souhaitez pas changer ; tout en changeant ces virgules par des points quand elles sont dans des champs numériques.
Les champs de notre fichier sont séparés par des tabulations ; on ne doit bien sûr pas toucher aux chiffres ; et on ne sait pas combien de chiffres seront avant et après cette virgule. Arggghh ! Exemple :
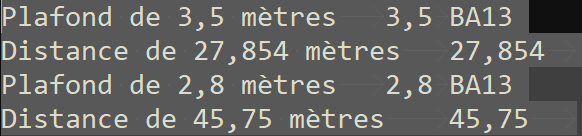
Héhé, rassurez-vous il y a une solution :
(?:\t|^)\d+\K,(?=\d+(?:\t|$))
Les mauvaises géométries dans un WKT
Pour trouver les lignes ou polygones constitués d'un seul point :
LINESTRING( |)\(( |)\d*\.\d* \d*\.\d*( |)\)
MULTILINESTRING( |)\(( |)\d*\.\d* \d*\.\d*( |)\)
POLYGON( |)\(\(( |)\d*\.\d* \d*\.\d*( |)\)\)
MULTIPOLYGON( |)\(\(( |)\d*\.\d* \d*\.\d*( |)\)\)
Pour chercher les coordonnées négatives, ajoutez :
\-
Pour remplacer les fausses lignes par exemple, par des points :
Remplacer LINESTRING(?=( |)\(( |)\d*\.\d* \d*\.\d*( |)\)) par POINT.
Dates
Format date français (exemple : 01/01/2023)
Ici personnalisé pour que l'année se trouve entre 1990 et 2029 :
(([0-2][0-9])|(3[0-1]))/((0[0-9])|(1[0-2]))/((199[0-9]|20[0-2][0-9]))
Dates au format français antérieures ou égales à 1980
/(1[0-9][0-7]\d{1}|1980)
Récupérer ses fichiers de configurations FTP
Bien pratique quand vous utilisez le plugin NPP et que vous souhaitez traverser les mises à jour sans trop de problèmes.
Emplacement du fichier contenant les confs :
AppData \ Roaming \ Notepad++ \ plugins \ config \ NppFTP \ NppFTP.xml
Chercher avec des exclusions
Exemple pour exclure le caractère à dans une recherche de tout autre caractère (\w) suivi d'un +:
(?!à)\w\+
Et parfois il faudra faire une petite variante :
(?<!à)\w\+