Avant toute manipulation un peu tordue, on ne le répétera jamais assez : les SIG ne sont pas autosuffisants. Cependant, parfois, ils peuvent créer de la donnée seulement à partir d'autres données. De la donnée nouvelle, plus riche que la donnée d'origine ou du moins, valorisée à partir de croisement de données (data mining).
 Mise en situation, dans le domaine de... allez, du géomarketing : vous êtes géomaticien, dans une société de géomarketing. Les développeurs ont déjà mis au point un programme accrochant les IRIS environnants à partir d'un point en entrée et selon plusieurs facteurs (géographiques, statistiques, données clients...). Il s'agit donc d'un programme de calcul de zones isochrones1, qui comme tous programmes de zones isochrones, peut être amélioré.
Mise en situation, dans le domaine de... allez, du géomarketing : vous êtes géomaticien, dans une société de géomarketing. Les développeurs ont déjà mis au point un programme accrochant les IRIS environnants à partir d'un point en entrée et selon plusieurs facteurs (géographiques, statistiques, données clients...). Il s'agit donc d'un programme de calcul de zones isochrones1, qui comme tous programmes de zones isochrones, peut être amélioré.
Le programme existe et marche déjà très bien. Il fait l'objet d'une application web facturée 15 000 € l'abonnement annuel (ou mensuel, je ne sais plus...). À ce prix là bien sûr, les indicateurs utilisés pour dessiner les zones ne prennent en compte qu'un nombre restreint de variables. Si le client veut plus de précision, ou une actualisation des données plus régulière, il doit souscrire un abonnement plus cher.
Ainsi votre employeur vous demande (ou vous lui proposez) de créer une couche qualifiant les 50 000 IRIS par leur potentiel accélérant ou freinant. Vous disposez des tronçons routiers, des voies ferrées et des fleuves (en lignes, avec attributs mentionnant les types de routes, de chemins de fer et la largeur des fleuves), et de l’occupation des sols (en polygones, eaux et forêts notamment).2
Vous avez déjà une certaine qualification de l'occupation des surfaces et de la capacité à s'y déplacer. Mais cette qualification est séparée de la couche des IRIS (disséminée dans les autres couches). Or on vous demande bien de calculer des champs sur des caractères freinants et accélérants par IRIS. L'enjeu est donc de rationnaliser vos entités géographiques par rapport à vos IRIS.
Comment ? Et bien cela va sans doute commencer par de petits découpages géométriques. Nous utiliserons ici ArcGIS pour les besoins de la démonstration, ses plugins permettant de fonctionner étape par étape et de façon très lisible pour l'exercice3.
Le caractère freinant
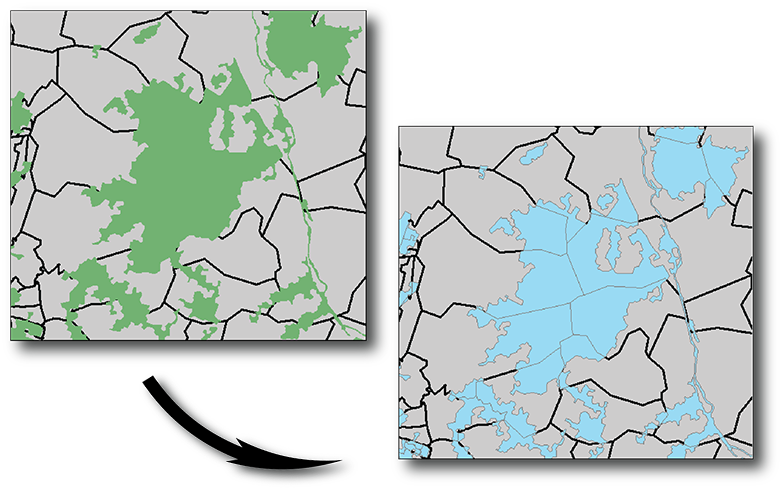
Commençons par un champ freinant. Un requêtage des valeurs uniques sur la couche de l'occupation des sols (ouvrez l'utilitaire de requêtage attributaire, choisissez la couche sol, le champ NATURE, puis faites Get uniques values, l'équivalent d'un select distinct en SQL) nous indique que les polygones sont du Bâti, de l'Eau ou des Forêts. Nous pouvons donc tous les considérer comme des éléments freinants (détail discutable mais plus tard nos éléments accélerants équilibreront peut-être ce biais. Peu importe pour la démonstration).
 Découpage
Découpage
Découpons nos polygones d'occupation des sols sur nos IRIS grâce à l'outil Clip de l'ArcToolBox3.
Mettez vos IRIS en entrée (Input features). La couche des sols est l'entité à découper (Clip features). Prenez l'habitude de renommer proprement votre couche en sortie (Output feature class, le résultat du traitement que vous vous apprêtez à lancer), et dans un répertoire bien identifié (bannissez les chemins contenant des espaces ou des caractères spéciaux). Nous la nommerons ici element_frein. Lancez le traitement.
Jointure spatiale
Constatez en sortie que element_frein nous livre bien des portions d'éléments freinants par IRIS (environ 40 000 entités) mais a aussi conservé les attributs de la couche en entrée, nos IRIS. ArcGIS ne s'est donc pas contenté de découper géométriquement en fonction d'une superposition, mais a aussi fait une jointure spatiale en fonction de cette superposition. Jointure permettant de ramener les informations des IRIS sur les polygones de sol découpé.
Je crois également que le plugin a fusionné les polygones originaux. Si vous souhaitiez les distinguer en fontion d'attributs, c'est trop tard. Mais rien n'empêche de refaire la même manipulation en sens inverse, ou même autrement, peu importe pour la suite.
Calcul des surfaces
Nous disposons maintenant, sur 2 couches de polygones différents, des codes IRIS permettant d'identifier les IRIS d'appartenance de façon unique. Retenons cela avant de calculer la surface de nos éléments freinants dans un nouveau champ.
Pour rappel, l'ajout d'un champ dans ArcGIS se fait sans passer en mode édition. Vous ouvrez directement la table attributaire de element_frein, puis vous rentrez dans ses options via l'icône en haut à gauche de la table. Vous ajoutez un champ nommé surf_frein, de type flottant, laissez les autres options par défaut.
Ensuite, un clic droit sur l'intitulé de ce champ vous permettra d'y calculer les géométries des entités, même hors mode édition. Choisissez donc d'y calculer la surface en km2. Faites la même chose pour la couche IRIS, afin de caluler la surface des 50 000 IRIS dans un champ nommé surface, en km2 également.
Quelques vérifications
Maintenant que nous possèdons les surfaces des élements freinants par IRIS, et celles des IRIS, nous allons pouvoir établir un rapport entre elles, pour calculer par exemple un pourcentage : le pourcentage de surface freinante par IRIS. Le programme pourra ainsi dire, en fonction d'un niveau de tolérance en entrée : « Ah, cet IRIS a un fort potentiel freinant, donc je n'y étends pas ma zone isochrone ».
Mais sommes-nous sûr qu'ArcGIS a bien fusionné tous nos polygones d'occupation des sols pendant le découpage ? Car pour rappel, nous n'avons pas eu la main sur ça, et il nous faut bien la somme de la surface de tous les élements freinants par IRIS si on veut calculer un pourcentage.
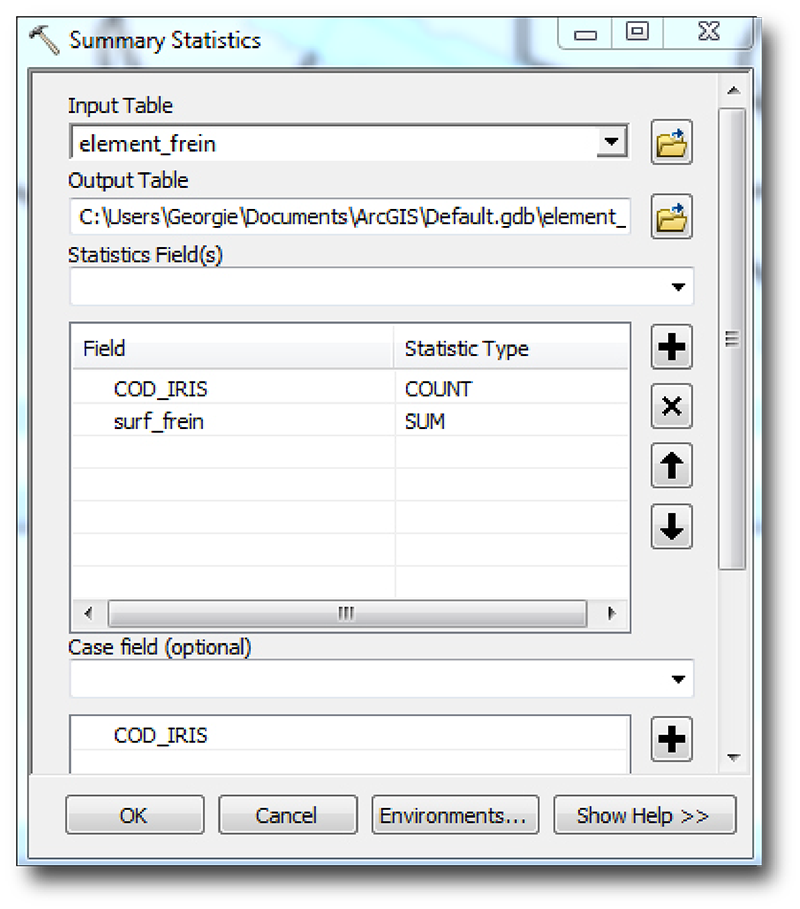 L'outil Summary statictics de l'ArcToolBox va nous permettre d'effectuer l'équivalent de requête de regroupement SQL, afin de vérifier combien de polygones d'occupation des sols existent par IRIS, tout en sommant leur surface.
L'outil Summary statictics de l'ArcToolBox va nous permettre d'effectuer l'équivalent de requête de regroupement SQL, afin de vérifier combien de polygones d'occupation des sols existent par IRIS, tout en sommant leur surface.
Mettez vos portions de sols découpés en entrée (element_frein), ajoutez les champs COD_IRIS et surf_frein en champs à calculer. Nous souhaitons savoir combien de fois un COD_IRIS revient dans notre couche, il s'agit donc d'un comptage (COUNT) ; et additionner les surfaces des polygones d'un même COD_IRIS, il s'agit là d'une somme (SUM). Le regroupement va se faire sur le code IRIS, c'est donc le Case field indispensable (le group by en SQL). L'équivalent en requête SQL aurait été :
select cod_iris, count(cod_iris), sum(surf_frein) from element_frein group by cod_iris
Nommez votre table de sortie comptage1 et lancer le traitement. Ouvrez puis triez vos résultats sur le champ ayant compté le nombre de polygones (COUNT_COD_IRIS). Nous constatons bien que les polygones avaient déjà été fusionné par IRIS ; que seul 2 polygones dont le COD_IRIS est absent ont été ici fusionnés ; et que nous avons ajouté le champ de comptage pour rien puisqu'ArcGIS a automatiquement ajouté un champ FREQUENCY à cet effet...
OK, tout va bien. Mais si cela n'avait pas été le cas il nous aurait suffit, pour la jointure qui va suivre, d'utiliser notre table comptage1 plutôt que la table originelle element_frein. Gardons cela en tête pour plus tard.
Jointure attributaire
Nous commençons à apercevoir le bout du tunnel au terme duquel nous pourrons utiliser nos différents champs comme dans un simple fichier Excel. En effet il serait plus confortable de rapatrier notre champ surf_frein dans notre table des IRIS, on y verrait plus clair pour d'éventuels calculs impliquant nos champs de surface. Il s'agit donc de joindre notre couche element_frein à la couche iris.
Pour cela, faites un clic droit sur votre couche des IRIS, puis créez une jointure. Mentionnez le COD_IRIS en champ de liaison, choisissez votre couche à joindre element_frein, et bien sûr le champ unique en commun COD_IRIS. Pour plus de lisibilité dans votre couche, conservez tous les enregistrements. Vous pouvez aussi valider la jointure et ajouter un index.
Ces paramètres précisés, lancez la jointure et retournez voir la table attributaire des IRIS : de nouveaux champs sont apparus. Vous pouvez désactiver les champs inutiles (clic droit sur l'intitulé), et déplacer les autres. Vous avez maintenant ce type de table avec nos 2 champs surfaciques indispensables :
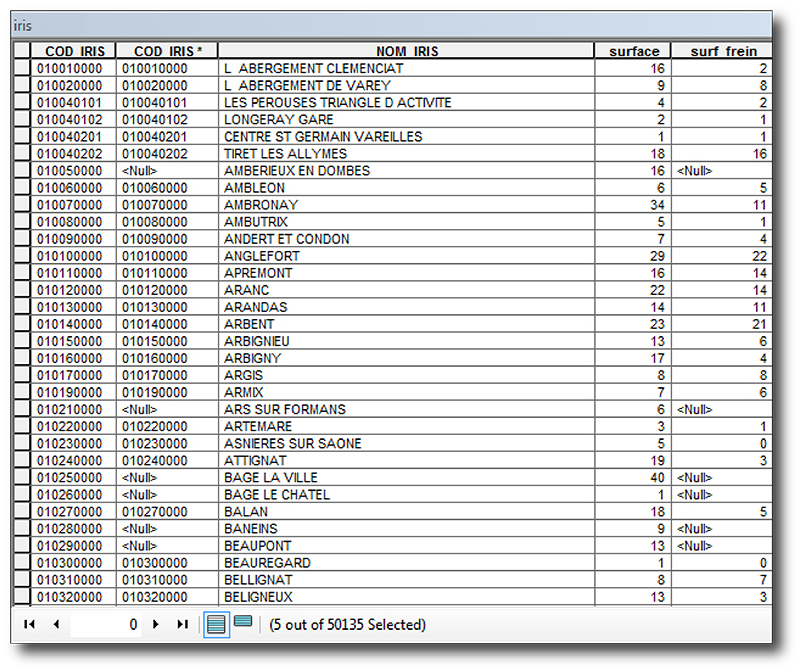
Souvenez tout de même qu'une jointure est un objet virtuel, les données n'ont pas été copiées-collées d'une table à une autre, mais sont directement liées (l'équivalent d'une vue SQL, ou view). Les avantages pouvant être la répercussion des mises à jour dans les tables liés, la facilité de lecture, le regroupement possible des enregistrements, afin de les utiliser dans des calculs ou autre...
Pourcentage de surface ralentissante
Jeu d'enfant désormais, de calculer le pourcentage de surface ralentissante par rapport à la surface totale. Créez un champ nommé frein_ptg (toujours en float). Il est nativement préfixé par iris pour vous rappeler que vous êtes sur une couche jointe et que ce champ a été ajouté à la couche iris.
Ouvrez le Field calculator sur ce champ (clic droit sur l'intitulé) et calculez-y le pourcentage. Soit la surface de nos éléments freinants divisée par la surface de l'IRIS, le tout multiplié par 100. En double-cliquant sur les valeurs proposées par le Field calculator (intitulés de champs, opérateurs...), vous pouvez construire votre requête. Sinon, la syntaxe SQL est la suivante :
([element_frein.surf_frein] / [iris.surface]) * 100
En bon SQL, le nom des tables d'appartenance préfixe le nom des champs, séparé par un point. La seule différence avec du SQL classique étant l'utilisation de crochets pour baliser nos champs (comme sur Access d'ailleurs). Lancez le traitement4.
Enfin... Vos résulats vont bien de 0 à 100. Vous avez extrait de la donnée géographique en croisant deux autres jeux de données, et elle parle encore plus une fois rationnalisée en pourcentage puisqu'autorisant la comparaison entre IRIS.
Vous pouvez rompre la jointure ou fermer votre mxd, le champ frein_ptg a été créé en dur dans votre couche originale des IRIS. Ce sera notre variable freinante.
Le caractère accélérant
Attaquons maintenant le potentiel accélérant des IRIS. Pour les besoins de la démonstration, nous n'utiliserons que la couche des tronçons routiers et sans distinction attributaire, mais vous voyez d'ici les finitions possibles et négociables.
Vous avez compris la manœuvre : pareil que précédemment mais avec des lignes. On souhaite dans un 1er temps connaître le nombre de kilomètres de routes par IRIS, puis dans un 2nd temps les rationnaliser par rapport au périmètre des IRIS (et pourquoi pas ?).
Identification
« Facile ! Je n'ai qu'à découper mes routes sur mes IRIS, comme tout-à-l'heure ! »
Hihi... Oui l'année prochaine peut-être, suite à une mise à jour du plugin... Pour l'heure il semble que l'outil Clip ne clipe pas autre chose que des polygones, cela du moins quand il reçoit déjà des polygones en entrée, affaire à suivre...
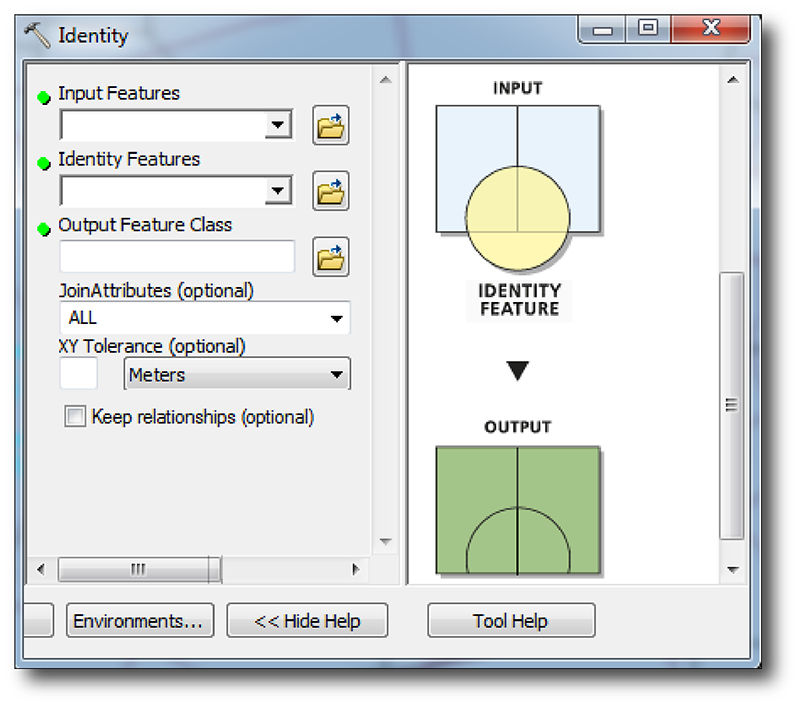 Qu'à cela ne tienne, c'est l'outil Identity qui nous permettra d'arriver à nos fins, en faisant à peu près exactement la même chose, mais sans nous jeter comme des malpropres sous prétexte que nous n'utilisons pas que des polygones, et sans cette histoire de fusion automatique des entités de sortie.
Qu'à cela ne tienne, c'est l'outil Identity qui nous permettra d'arriver à nos fins, en faisant à peu près exactement la même chose, mais sans nous jeter comme des malpropres sous prétexte que nous n'utilisons pas que des polygones, et sans cette histoire de fusion automatique des entités de sortie.
Cette fois, c'est vos tronçons routiers qui passent en entrée pour être identifiés par rapport à vos IRIS (Identify features). Votre entité en sortie sera donc bien un shape de lignes (nommons-le route_identite), avec là encore une jointure spatiale automatique qui a ramené les attributs de l'entité identifiante (dont le fameux code IRIS). 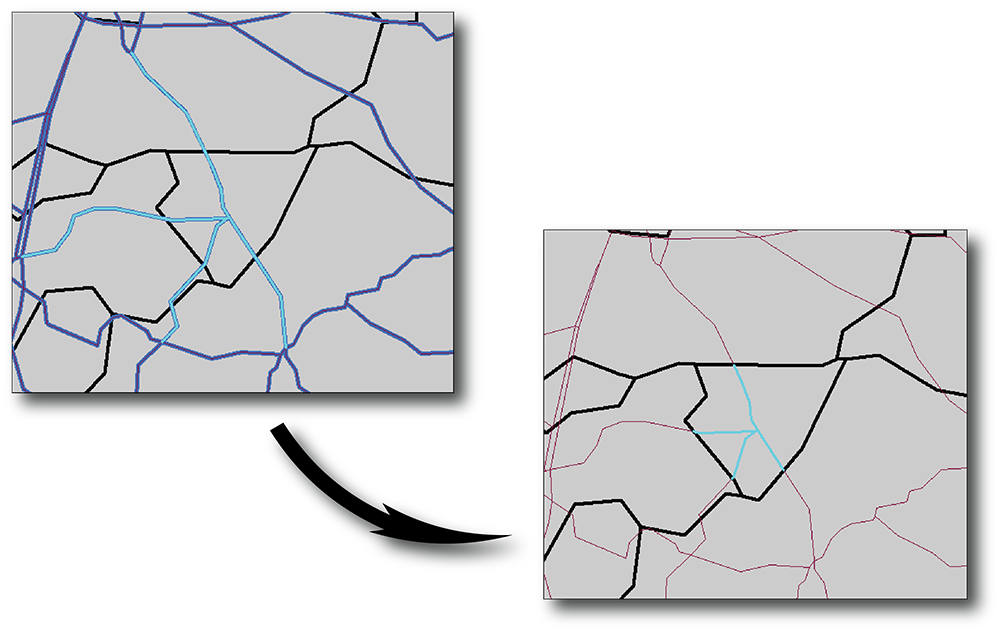
Malheureusement et contrairement à l'outil Clip, si l'outil Identity a bien découpé les routes sur nos IRIS la jointure spatiale n'a pas fusionné les différents tronçons de routes par IRIS... Bon, calculons déjà la longueur de ces tronçons, dans un nouveau champ nommé longueur, en float et en kilomètre. Je vous laisse faire avant de passer à la suite.
Requête de regroupement
Très bien, maintenant il nous faut donc additionner nous-mêmes ces longueurs de tronçons par IRIS. Nous utiliserons comme précemment l'outil Summary statistics pour sommer le champ longueur regroupé sur le champ COD_IRIS. Puis, jointure à partir de la couche IRIS afin de ramener le nouveau champ SUM_LONGUEUR ainsi créé.
Indicateur de disponibilité routière
Pas besoin de dessin pour la suite : ajout d'un champ peri pour calculer le périmètre des IRIS en kilomètre. Ajout d'un champ long_indic pour calculer le rapport au périmètre, et hop ! Somme des tronçons divisée par périmètre, le tout multiplié par cent pour faire plus joli.
Notez que le champ long_indic n'est pas un vrai pourcentage sur les périmètres. En effet la somme des routes d'un IRIS peut parfois être supérieure à son périmètre. Dans notre cas et hormis quelques valeurs aberrantes5, nous parlerons plutôt d'indicateur de disponibilité routière, pouvant aller jusqu'à presque 300, soit 3 fois le périmètre de l'IRIS (l'IRIS de l'aéroport de Roissy par exemple).
Notre indicateur servira lui-même de variable accélérante. On pouvait sans doute trouver mieux pour le calculer (tri sur les attributs des routes, vérification de la non-superposition de routes...), mais on voit ici qu'avec un minimum de données, la limite n'est plus que celle de l'imagination.
[À propos du programme]
Avez-vous remarqué que votre employeur ne vous a pas demandé la traduction SQL de l'ensemble des opérations réalisées ? Qui pourrait être obtenue sous la forme d'un script, lui-même intégré au calcul des zones isochrones (plus facile à dire qu'à faire, mais vous me suivez).
Non, on vous demande bien une simple couche géographique. Et c'est elle qui va être intégrée au web-SIG6, avec sans doute un rapatriement des champs que vous avez calculés sur la couche des IRIS déjà utilisée par l'application.
Vous devinez alors que le programme ne va rien calculer dynamiquement. Il va plutôt sélectionner des zones isochrones pré-calculées en fonction d'une requête utilisateur (un clic en fin de formulaire). De nombreuses applications web fonctionnent de cette façon, avec les calculs réalisés en amont et servis en dur depuis une base de données des résultats (avec d'éventuelles mises à jour automatique, mais encore en amont).
Pour l'affichage de zones isochrones fines (ici par IRIS, contenant des informations statistiques que bien sûr nous voulons afficher) ceci n'est pas anodin. En effet les résultats sont autant d'IRIS que le nombre de zones isochrones potentielles peut en contenir. Chaque IRIS étant lié à plusieurs zones isochrones, et présent autant de fois qu'il appartient à des zones isochrones différentes. Soit une table de plusieurs dizaines de millions de lignes, selon les types de zones proposées par le programme (à 15 minutes, 30 minutes, à pied, en voiture...).
Mieux vaut bien indexer7 sa table...
- 1. Zone isochrone : surface recouvrant un ensemble de points accessibles par rapport à un autre point, en une vitesse donnée et dans un maximum de temps (exemple : la zone géographique dans laquelle un camion de pompier peut se rendre en moins de 10 minutes). L'usage du terme ou de ce qu'il représente est parfois un peu galvaudé, l'expression étant elle-même sujet à caution (des surfaces délimitant des points, eux-mêmes censés être liés à des trajets, donc des lignes...) et les calculs pouvant impliquer un grand nombre de paramètres (et faisant l'objet de choix humains). En géomarketing le concept de zone isochrone est très lié à celui de zone de chalandise (surface des points à partir desquels la clientèle accepte de se rendre dans un magasin, ou zone client).
- 2. Ce paragraphe contient les liens de téléchargement des 5 couches nécessaires, en fichiers shapes zippés. Retrouvez les également ici :
- iris (Les IRIS de l’INSEE, 2019, polygones)
- troncons_routes (les routes de l’IGN, 2011, lignes)
- chemin_de_fer (les voies férrées de l’IGN, 2011, lignes)
- eau (les fleuves de l’IGN, 2011, lignes)
- sol (L’occupation des sols selon l’IGN, 2011, polygones) - 3. Les images de cet article sont cliquables pour affichage en grand format, et contiennent des notes supplémentaires.
- 4. Vous pouvez avoir quelques erreurs ou ralentissement pendant le calcul, peut-être dû au caractère null dans les IRIS n'ayant pas d'éléments freinants. Essayez alors de refaire votre jointure mais sans conserver tous les enregistrements joints (No keep all, je vous laisse explorer les options disponibles, très intéressantes et correspondantes encore à du SQL classique). Plus simplement, si tous vos champs sont en float, vous pouvez forcer le traitement sans crainte. Si malgré tout, ces problèmes de performances persistent (sigh !), c'est sans doute dû au poids des 50 000 IRIS à calculer. Vous pouvez alors exporter votre jointure dans un nouveau shape pour y faire le calcul sans passer par une jointure ; ou encore ouvrir une session d'édition sur la couche à calculer (ce qui devrait augmenter les ressources utilisées par le logiciel pour les traitements sur cette couche). Vous pouvez aussi tout importer sur PostGIS...
- 5. Ces valeurs aberrantes sont sans doute dûes à des problèmes géométriques sur la couche des IRIS (des polygones mal construits ou mal superposés, j'en ai 4 dans ce cas) et dont la code IRIS a sauté. La somme des tronçons s'est alors faite de façon plus-ou-moins aléatoire. Vous les repérez facilement en l'absence de code IRIS.
- 6. Web-SIG : se dit d'applications web très orientées Système d'Information Géographique, du simple affichage de couches aux géo-traitements.
- 7. Indexer un champ dans une base de données SQL (ajouter un index sur un champ) permet de mieux le référencer dans la BDD, en l'inscrivant à un niveau plus bas et indépendant de la saisie, pour améliorer les accès aux enregistrements liés. Une clé primaire est une forme d'index très efficace sur les champs à valeurs uniques (et idéalement auto-incrémentés en chiffre entier), mais d'autres champs à valeur non-uniques peuvent recevoir un index, notamment ceux fréquemment requêtés (des dates par exemple) ou contenant des valeurs récurrentes (des mots-clés...). Les champs spatiaux des bases de données spatiales font aussi souvent l'objet d'un index spatial. A contrario, ajouter trop d'index dans une table peut être contre-productif.